A tuned GRU beat LoRA-fine-tuned GPT-2, here's why
A 117-million-parameter transformer lost to a small recurrent network on every metric I measured. The headline is tempting but wrong. The real lesson is quieter: most "transformers win" results are really "the baseline was never tuned" results.
The setup
The task was open-domain dialogue generation on the Cornell Movie-Dialogs Corpus, about 53,107 conversational pairs. I built three models: a GRU-based sequence-to-sequence model, an LSTM variant, and a GPT-2 fine-tuned with LoRA. The expectation, going in, was the obvious one: the pretrained transformer should walk it.
What actually happened
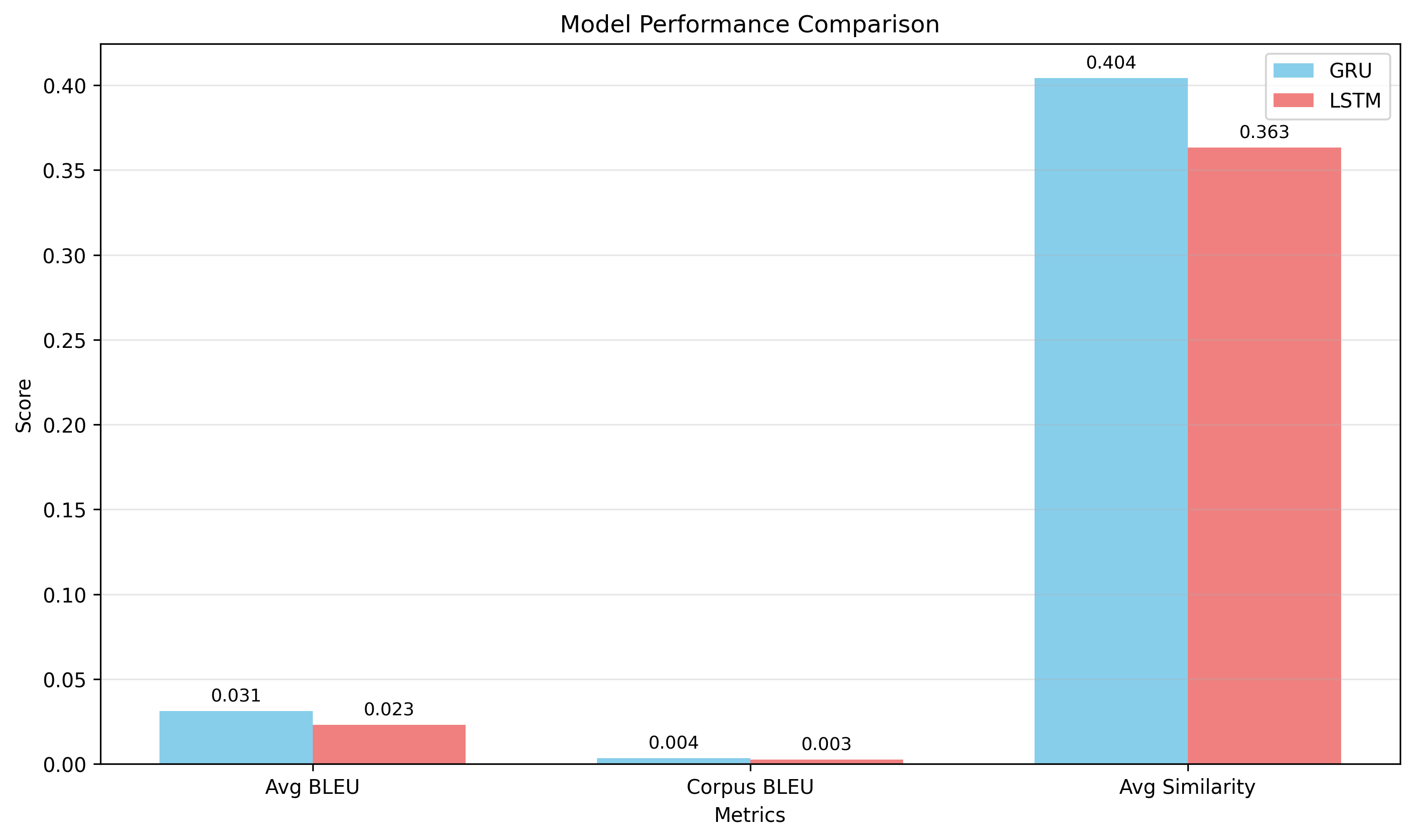
The well-tuned GRU won on every metric, most starkly on perplexity, where lower is better.
| Model | Perplexity (↓) | Relative |
|---|---|---|
| GRU seq2seq (tuned) | 12.39 | best |
| GPT-2 + LoRA | 45.62 | 3.7× higher |
The GRU's perplexity was 3.7× lower than the LoRA-fine-tuned GPT-2's, and its BLEU was roughly 2.8× higher. A model with a fraction of the parameters produced more coherent, more on-distribution replies.
Why the small model won
Three reasons, none of which are "GRUs are secretly better than transformers."
- The metric matches the small model's home turf. Perplexity rewards fitting the training distribution tightly. A seq2seq model trained end-to-end on this exact corpus does that naturally; a frozen-backbone GPT-2 nudged by a thin LoRA adapter is pulled toward its vast pretraining distribution, which is not 1980s movie banter.
- LoRA changed very little of GPT-2. Low-rank adapters update a tiny slice of the weights. That's the point, it's cheap, but on a narrow, stylistically peculiar corpus, "cheap and barely changed" can mean "never really adapted."
- The GRU was actually tuned. Hidden size, layers, teacher forcing, learning-rate schedule, decoding. The transformer got the default treatment everyone gives baselines they assume will win anyway.
The real lesson
This is not an argument against transformers. On a large, diverse corpus, or judged by human-rated coherence rather than corpus perplexity, GPT-2 might well pull ahead. The honest takeaway is about process:
- Tune the baseline as hard as the model you're rooting for. An untuned baseline isn't a baseline; it's a strawman.
- State which metric you optimised and why it suits the data. "Won on perplexity" and "won on human preference" are different claims.
- Be suspicious of results that flatter your favourite architecture. They're the ones most likely to be hiding an unfair comparison.
The most useful thing the GRU did wasn't winning. It was forcing me to explain why it won, and that explanation is worth more than the leaderboard row.
Read the full dialogue case study →