← Back to home
Writing
Notes on honest evaluation
Short write-ups on the part of machine learning that doesn't fit in a leaderboard: leakage, baselines, and why a good number is usually wrong until proven otherwise.
Evaluation · 6 min read
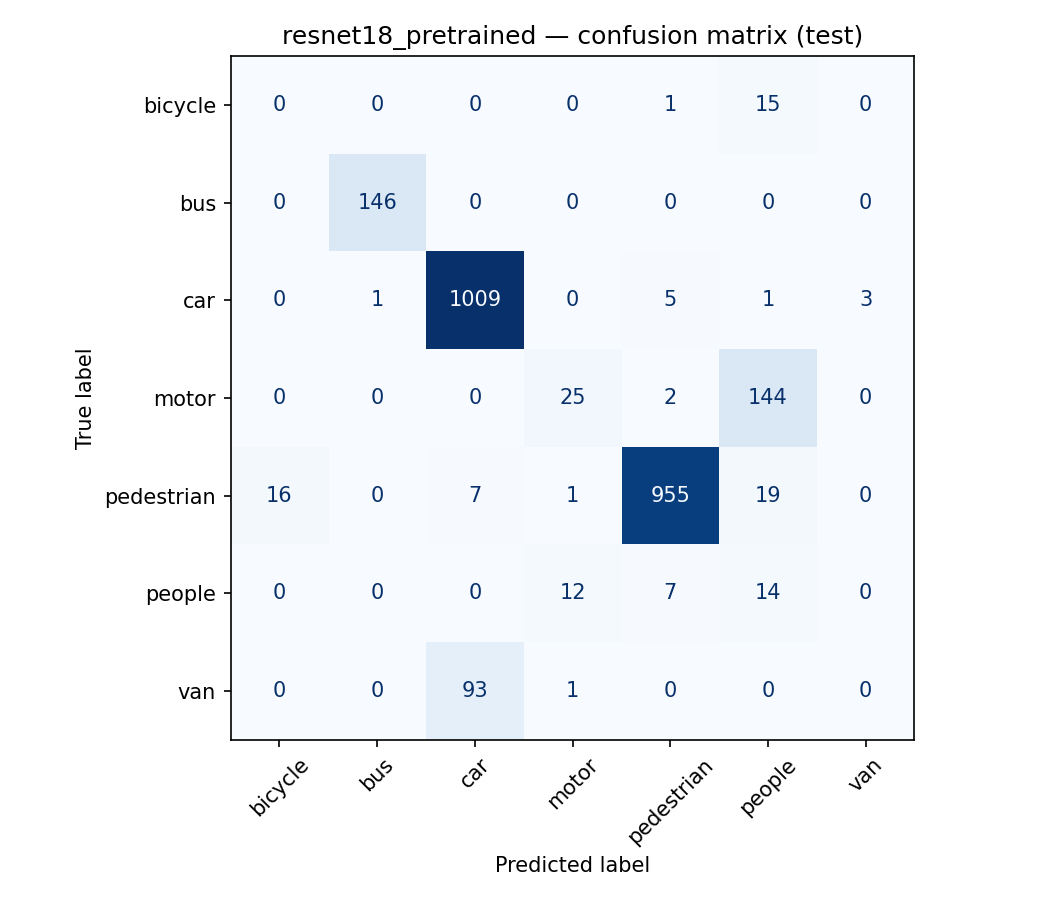
How a naïve train/test split inflated my UAV F1 by 0.5
The same model, the same data, and a macro-F1 that fell from 0.78 to 0.26 the moment I split the data honestly. A walk through the most expensive bug in ML.
12 Jun 2026 Read →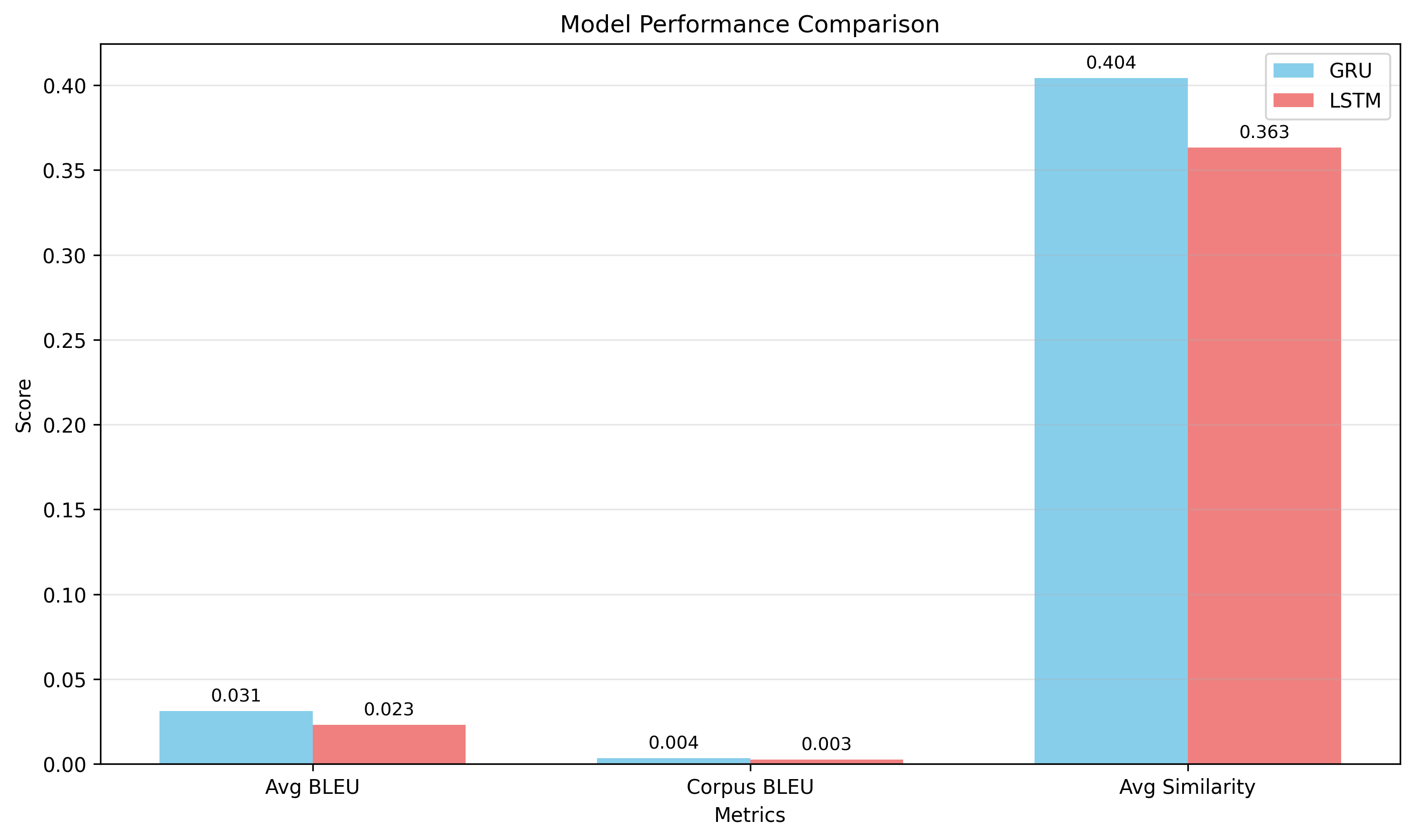
Baselines · 7 min read
A tuned GRU beat LoRA-fine-tuned GPT-2, here's why
A 117M-parameter transformer lost to a small recurrent net on every metric. Not because transformers are bad, but because the baseline was done properly.
20 Jun 2026 Read →