How a naïve train/test split inflated my UAV F1 by 0.5
The same model. The same data. A macro-F1 that fell from 0.78 to 0.26 the moment I split the data honestly. This is the most expensive bug in machine learning, and it almost never throws an error.
The task
I had 8,903 object crops, car, bus, truck, van, person, bicycle, motorcycle, extracted from a 146-frame UAV video sequence, to be sorted into seven classes. Two things make it harder than a normal image-classification dataset. First, severe class imbalance: cars are about 42% of the samples, bicycles barely 1%. Second, and far more dangerous: the crops come from video.
Why video is a trap
A car in frame 12 and the same car in frame 13 are almost the same pixels, a few degrees of motion apart. They are, for all practical purposes, duplicates. If you shuffle every crop into one pile and randomly assign 20% to a test set, that test set fills up with near-copies of images the model trained on.
The model isn't generalising. It's recognising photographs it has already memorised. And the score looks fantastic, because in a sense the model is right, it just answered the wrong question.
The two splits
I trained the same pipeline twice. Once with a naïve random split, once with a track-aware split, where every crop of a given object instance is forced entirely onto one side of the train/test divide, so the model is genuinely tested on objects it has never seen.
| Split | Accuracy | Macro-F1 |
|---|---|---|
| Naïve random split | 0.906 | 0.776 |
| Track-aware split (honest) | 0.803 | 0.256 |
Accuracy barely flinched: it dropped from 0.91 to 0.80, which you might wave away. But macro-F1 collapsed from 0.78 to 0.26. That half-point gap is the leakage, made visible.
Why accuracy lied and macro-F1 told the truth
Accuracy is dominated by the majority class. Get all the cars right and you're already at ~42%. Macro-F1 weights every class equally, so it exposes what happens to the rare ones, bicycles, motorcycles, vans. On the honest split, the model had genuinely never seen those rare instances, and its performance on them cratered. The naïve split had quietly shown it test-set bicycles during training.
The lesson isn't "macro-F1 good, accuracy bad." It's pick the metric that can be embarrassed by your failure mode. Here the failure mode was rare classes, and only macro-F1 was honest about them.
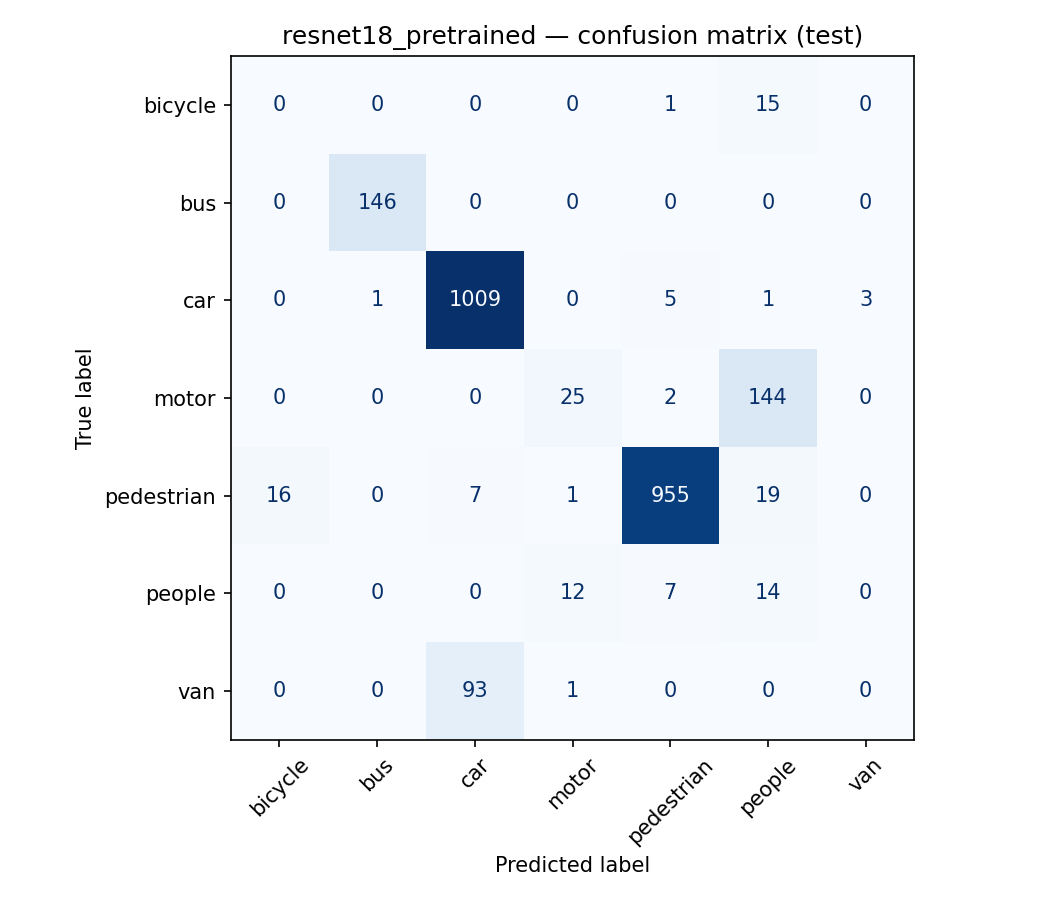
What I do now, every time
- Before touching a model, ask: what makes two samples near-duplicates? Time, patient, document, user, device, geography. Split on that, not on the row.
- Treat a suspiciously high score as a bug report, not a celebration. Good numbers are wrong until proven otherwise.
- Report the metric that can fail loudly. If a metric can't be embarrassed by your worst case, it isn't measuring it.
- Write the split logic down and version it, so "we evaluated honestly" is reproducible rather than remembered.
The 0.78 was the number that would have gone in a slide deck. The 0.26 is the number that would have survived contact with reality. Knowing the difference is most of the job.
Read the full UAV case study →